微信-SQLite修复
2017 - 06 - 20
Posted by WeMobileDev
前言
长久以来SQLite DB都有损坏问题,从Android、iOS等移动系统,到Windows、Linux 等桌面系统都会出现。由于微信所有消息都保存在DB,服务端不保留备份,一旦损坏将导致用户消息被清空,显然不能接受。
这次我们将深入介绍微信数据库修复的具体方案和发展历程。
我们的需求
具体来说,微信需要一套满足以下条件的DB恢复方案:
-
恢复成功率高。 由于牵涉到用户核心数据,“姑且一试”的方案是不够的,虽说 100% 成功率不太现实,但 90% 甚至 99% 以上的成功率才是我们想要的。
-
支持加密DB。 Android 端微信客户端使用的是加密 SQLCipher DB,加密会改变信息 的排布,往往对密文一个字节的改动就能使解密后一大片数据变得面目全非。这对于数据恢复 不是什么好消息,我们的方案必须应对这种情况。
-
能处理超大的数据量。 经过统计分析,个别重度用户DB大小已经超过2GB,恢复方案 必须在如此大的数据量下面保证不掉链子。
-
不影响体验。 统计发现只有万分之一不到的用户会发生DB损坏,如果恢复方案 需要事先准备(比如备份),它必须对用户不可见,不能为了极个别牺牲全体用户的体验。
经过多年的不断改进,微信先后采用出三套不同的DB恢复方案,离上面的目标已经越来越近了。
官方的Dump恢复方案
Google 一下SQLite DB恢复,不难搜到使用.dump命令恢复DB的方法。.dump命令的作用是将 整个数据库的内容输出为很多 SQL 语句,只要对空 DB 执行这些语句就能得到一个一样的 DB。
.dump命令原理很简单:每个SQLite DB都有一个sqlite_master表,里面保存着全部table 和index的信息(table本身的信息,不包括里面的数据哦),遍历它就可以得到所有表的名称和 CREATE TABLE ...的SQL语句,输出CREATE TABLE语句,接着使用SELECT * FROM ... 通过表名遍历整个表,每读出一行就输出一个INSERT语句,遍历完后就把整个DB dump出来了。 这样的操作,和普通查表是一样的,遇到损坏一样会返回SQLITE_CORRUPT,我们忽略掉损坏错误, 继续遍历下个表,最终可以把所有没损坏的表以及损坏了的表的前半部分读取出来。将dump 出来的SQL语句逐行执行,最终可以得到一个等效的新DB。由于直接跑在SQLite上层,所以天然 就支持加密SQLCipher,不需要额外处理。
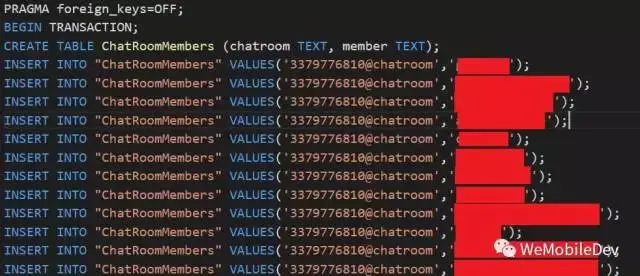
(图:dump输出样例)
这个方案不需要任何准备,只有坏DB的用户要花好几分钟跑恢复,大部分用户是不感知的。 数据量大小,主要影响恢复需要的临时空间:先要保存dump 出来的SQL的空间,这个 大概一倍DB大小,还要另外一倍 DB大小来新建 DB恢复。至于我们最关心的成功率呢?上线后,成功率约为30%。这个成功率的定义是至少恢复了一条记录,也就是说一大半用户 一条都恢复不成功!
研究一下就发现,恢复失败的用户,原因都是sqlite_master表读不出来,特别是第一页损坏, 会导致后续所有内容无法读出,那就完全不能恢复了。恢复率这么低的尴尬状况维持了好久, 其他方案才渐渐露出水面。
备份恢复方案
损坏的数据无法修复,最直观的解决方案就是备份,于是备份恢复方案被提上日程了。备份恢复这个 方案思路简单,SQLite 也有不少备份机制可以使用,具体是:
-
拷贝: 不能再直白的方式。由于SQLite DB本身是文件(主DB + journal 或 WAL), 直接把文件复制就能达到备份的目的。
-
Dump: 上一个恢复方案用到的命令的本来目的。在DB完好的时候执行
.dump, 把 DB所有内容输出为 SQL语句,达到备份目的,恢复的时候执行SQL即可。 -
Backup API: SQLite自身提供的一套备份机制,按 Page 为单位复制到新 DB, 支持热备份。
这么多的方案孰优孰劣?作为一个移动APP,我们关心的无非就是 备份大小、备份性能、 恢复性能 几个指标。微信作为一个重度DB使用者,备份大小和备份性能是主要关注点, 原本用户就可能有2GB 大的 DB,如果备份数据本身也有2GB 大小,用户想必不会接受; 性能则主要影响体验和备份成功率,作为用户不感知的功能,占用太多系统资源造成卡顿 是不行的,备份耗时越久,被系统杀死等意外事件发生的概率也越高。
对以上方案做简单测试后,备份方案也就基本定下了。测试用的DB大小约 50MB, 数据条目数大约为 10万条:
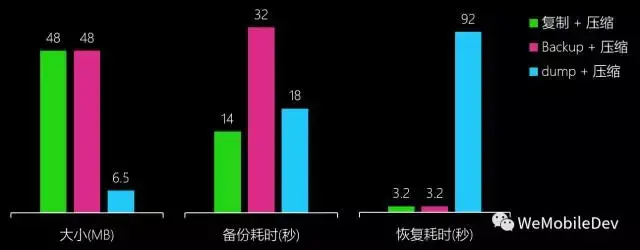
(图:备选方案性能对比)
可以看出,比较折中的选择是 Dump + 压缩,备份大小具有明显优势,备份性能尚可, 恢复性能较差但由于需要恢复的场景较少,算是可以接受的短板。
微信在Dump + gzip方案上再加以优化,由于格式化SQL语句输出耗时较长,因此使用了自定义 的二进制格式承载Dump输出。第二耗时的压缩操作则放到别的线程同时进行,在双核以上的环境 基本可以做到无额外时间消耗。由于数据保密需要,二进制Dump数据也做了加密处理。 采用自定义二进制格式还有一个好处是,恢复的时候不需要重复的编译SQL语句,编译一次就可以 插入整个表的数据了,恢复性能也有一定提升。优化后的方案比原始的Dump + 压缩, 每秒备份行数提升了 150%,每秒恢复行数也提升了 40%。
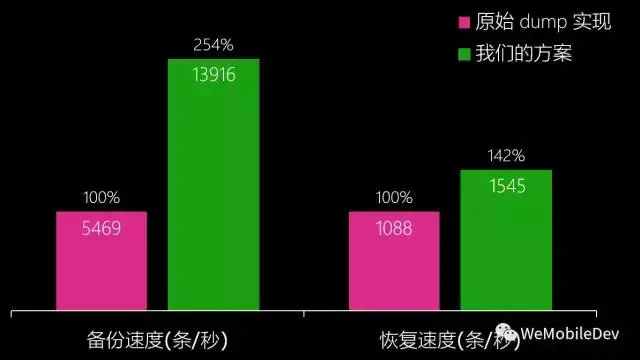
(图: 性能优化效果)
即使优化后的方案,对于特大DB备份也是耗时耗电,对于移动APP来说,可能未必有这样的机会 做这样重度的操作,或者频繁备份会导致卡顿,这也是需要开发者衡量的。比如Android微信会 选择在 充电并灭屏 时进行DB备份,若备份过程中退出以上状态,备份会中止,等待下次机会。
备份方案上线后,恢复成功率达到72%,但有部分重度用户DB损坏时,由于备份耗时太久, 始终没有成功,而对DB数据丢失更为敏感的也恰恰是这些用户,于是新方案应运而生。
解析B-tree恢复方案(RepairKit)
备份方案的高消耗迫使我们从另外的方案考虑,于是我们再次把注意力放在之前的Dump方案。 Dump 方案本质上是尝试从坏DB里读出信息,这个尝试一般来说会出现两种结果:
-
DB的基本格式仍然健在,但个别数据损坏,读到损坏的地方SQLite返回
SQLITE_CORRUPT错误, 但已读到的数据得以恢复。 -
基本格式丢失(文件头或
sqlite_master损坏),获取有哪些表的时候就返回SQLITE_CORRUPT, 根本没法恢复。
第一种可以算是预期行为,毕竟没有损坏的数据能 部分恢复。从之前的数据看, 不少用户遇到的是第二种情况,这种有没挽救的余地呢?
要回答这个问题,先得搞清楚sqlite_master是什么。它是一个每个SQLite DB都有的特殊的表, 无论是查看官方文档Database File Format,还是执行SQL语句 SELECT * FROM sqlite_master;,都可得知这个系统表保存以下信息: 表名、类型(table/index)、 创建此表/索引的SQL语句,以及表的RootPage。sqlite_master的表名、表结构都是固定的, 由文件格式定义,RootPage 固定为 page 1。

(图:sqlite_master表)
正常情况下,SQLite 引擎打开DB后首次使用,需要先遍历sqlite_master,并将里面保存的SQL语句再解析一遍, 保存在内存中供后续编译SQL语句时使用。假如sqlite_master损坏了无法解析,“Dump恢复”这种走正常SQLite 流程的方法,自然会卡在第一步了。为了让sqlite_master受损的DB也能打开,需要想办法绕过SQLite引擎的逻辑。 由于SQLite引擎初始化逻辑比较复杂,为了避免副作用,没有采用hack的方式复用其逻辑,而是决定仿造一个只可以 读取数据的最小化系统。
虽然仿造最小化系统可以跳过很多正确性校验,但sqlite_master里保存的信息对恢复来说也是十分重要的, 特别是RootPage,因为它是表对应的B-tree结构的根节点所在地,没有了它我们甚至不知道从哪里开始解析对应的表。
sqlite_master信息量比较小,而且只有改变了表结构的时候(例如执行了CREATE TABLE、ALTER TABLE 等语句)才会改变,因此对它进行备份成本是非常低的,一般手机典型只需要几毫秒到数十毫秒即可完成,一致性也容易保证, 只需要执行了上述语句的时候重新备份一次即可。有了备份,我们的逻辑可以在读取DB自带的sqlite_master失败的时候 使用备份的信息来代替。
DB初始化的问题除了文件头和sqlite_master完整性外,还有加密。SQLCipher加密数据库,对应的恢复逻辑还需要加上 解密逻辑。按照SQLCipher的实现,加密DB 是按page 进行包括头部的完整加密,所用的密钥是根据用户输入的原始密码和 创建DB 时随机生成的 salt 运算后得出的。可以猜想得到,如果保存salt错了,将没有办法得出之前加密用的密钥, 导致所有page都无法读出了。由于salt 是创建DB时随机生成,后续不再修改,将它纳入到备份的范围内即可。
到此,初始化必须的数据就保证了,可以仿造读取逻辑了。我们常规使用的读取DB的方法(包括dump方式恢复), 都是通过执行SQL语句实现的,这牵涉到SQLite系统最复杂的子系统——SQL执行引擎。我们的恢复任务只需要遍历B-tree所有节点, 读出数据即可完成,不需要复杂的查询逻辑,因此最复杂的SQL引擎可以省略。同时,因为我们的系统是只读的, 写入恢复数据到新 DB 只要直接调用 SQLite 接口即可,因而可以省略同样比较复杂的B-tree平衡、Journal和同步等逻辑。 最后恢复用的最小系统只需要:
-
VFS读取部分的接口(Open/Read/Close),或者直接用stdio的fopen/fread、Posix的open/read也可以
-
SQLCipher的解密逻辑
-
B-tree解析逻辑
即可实现。
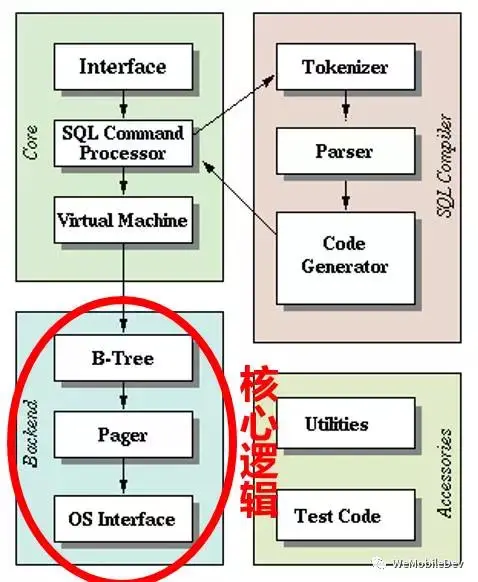
(图:最小化系统)
Database File Format 详细描述了SQLite文件格式, 参照之实现B-tree解析可读取 SQLite DB。加密 SQLCipher 情况较为复杂,幸好SQLCipher 加密部分可以单独抽出,直接套用其解密逻辑。
实现了上面的逻辑,就能读出DB的数据进行恢复了,但还有一个小插曲。我们知道,使用SQLite查询一个表, 每一行的列数都是一致的,这是Schema层面保证的。但是在Schema的下面一层——B-tree层,没有这个保证。 B-tree的每一行(或者说每个entry、每个record)可以有不同的列数,一般来说,SQLite插入一行时, B-tree里面的列数和实际表的列数是一致的。但是当对一个表进行了ALTER TABLE ADD COLUMN操作, 整个表都增加了一列,但已经存在的B-tree行实际上没有做改动,还是维持原来的列数。 当SQLite查询到ALTER TABLE前的行,缺少的列会自动用默认值补全。恢复的时候,也需要做同样的判断和支持, 否则会出现缺列而无法插入到新的DB。
解析B-tree方案上线后,成功率约为78%。这个成功率计算方法为恢复成功的 Page 数除以总 Page 数。 由于是我们自己的系统,可以得知总 Page 数,使用恢复 Page 数比例的计算方法比人数更能反映真实情况。 B-tree解析好处是准备成本较低,不需要经常更新备份,对大部分表比较少的应用备份开销也小到几乎可以忽略, 成功恢复后能还原损坏时最新的数据,不受备份时限影响。 坏处是,和Dump一样,如果损坏到表的中间部分,比如非叶子节点,将导致后续数据无法读出。
不同方案的组合
由于解析B-tree恢复原理和备份恢复不同,失败场景也有差别,可以两种手段混合使用覆盖更多损坏场景。 微信的数据库中,有部分数据是临时或者可从服务端拉取的,这部分数据可以选择不修复,有些数据是不可恢复或者 恢复成本高的,就需要修复了。
如果修复过程一路都是成功的,那无疑使用B-tree解析修复效果要好于备份恢复。备份恢复由于存在 时效性,总有部分最新的记录会丢掉,解析修复由于直接基于损坏DB来操作,不存在时效性问题。 假如损坏部分位于不需要修复的部分,解析修复有可能不发生任何错误而完成。
若修复过程遇到错误,则很可能是需要修复的B-tree损坏了,这会导致需要修复的表发生部分或全部缺失。 这个时候再使用备份修复,能挽救一些缺失的部分。
最早的Dump修复,场景已经基本被B-tree解析修复覆盖了,若B-tree修复不成功,Dump恢复也很有可能不会成功。 即便如此,假如上面的所有尝试都失败,最后还是会尝试Dump恢复。

(图: 恢复方案组合)
上面说的三种修复方法,原理上只涉及到SQLite文件格式以及基本的文件系统,是跨平台的。 实际操作上,各个平台可以利用各自的特性做策略上的调整,比如 Android 系统使用 JobScheduler 在充电灭屏状态下备份。
实践
众所周知,微信在后台服务器不保存聊天记录,微信在移动客户端所有的聊天记录都存储在一个 SQLite 数据库中,一旦这个数据库损坏,将会丢失用户多年的聊天记录。而我们监控到现网的损坏率是0.02%,也就是每 1w 个用户就有 2 个会遇到数据库损坏。考虑到微信这么庞大的用户基数,这个损坏率就很严重了。更严重的是我们用的官方修复算法,修复成功率只有 30%。损坏率高,修复率低,这两个问题都需要我们着手解决。
2、SQLite 损坏原因及其优化
我们首先来看 SQLite 损坏的原因,SQLite官网(http://www.sqlite.org/howtocorrupt.html)上列出以下几点:
-
文件错写
-
文件锁 bug
-
文件 sync 失败
-
设备损坏
-
内存覆盖
-
操作系统 bug
-
SQLite bug
但是我们通过收集到的大量案例和日志,分析出实际上移动端数据库损坏的真正原因其实就3个:
-
空间不足
-
设备断电
-
文件 sync 失败
我们需要针对这些原因一一进行优化。
2.1、优化空间占用
首先我们来优化微信的空间占用问题。在这之前微信的部分业务也做了空间清理,例如朋友圈会自动删除7天前缓存的图片。但是总的来说对文件空间的使用缺乏一个全局把控,全靠各个业务自觉。我们需要做得更积极主动,要让开发人员意识到用户的存储空间是宝贵的。我们采取以下措施:
-
业务文件先申请后使用,如果某个文件没有申请就使用了,会被自动扫描出来并删除;
-
每个业务文件都要申明有效期,是一天、一个星期、一个月还是永久存储;
-
过期文件会被自动清理。

对于微信之外的空间占用,例如相册、视频、其他App的空间占用,微信本身是做不了什么事情的,我们可以提示用户进行空间清理:

2.2、优化文件 sync
2.2.1、synchronous = FULL
设置SQLite的文件同步机制为全同步,亦即要求每个事物的写操作是真的flush到文件里去。
2.2.1、fullfsync = 1
通过与苹果工程师的交流,我们发现在 iOS 平台下还有 fullfsync (https://www.sqlite.org/pragma.html#pragma_fullfsync) 这个选项,可以严格保证写入顺序跟提交顺序一致。设备开发商为了测评数据好看,往往会对提交的数据进行重排,再统一写入,亦即写入顺序跟App提交的顺序不一致。在某些情况下,例如断电,就可能导致写入文件不一致的情况,导致文件损坏。
2.3、优化效果
多管齐下之后,我们成功将损坏率降低了一半多;DB损坏还是无法完全避免,我们还是得提高修复成功率。
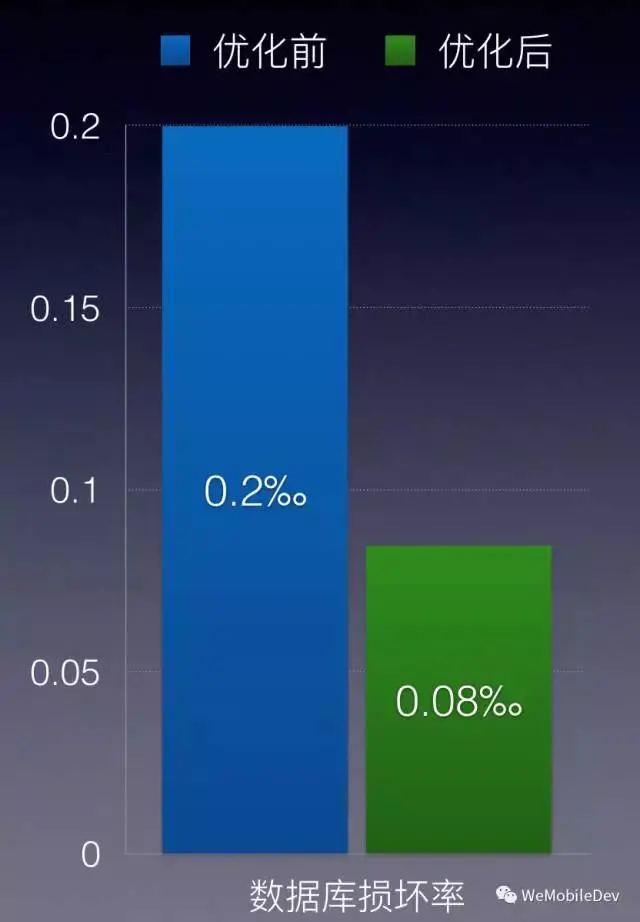
3、SQLite 修复逻辑优化
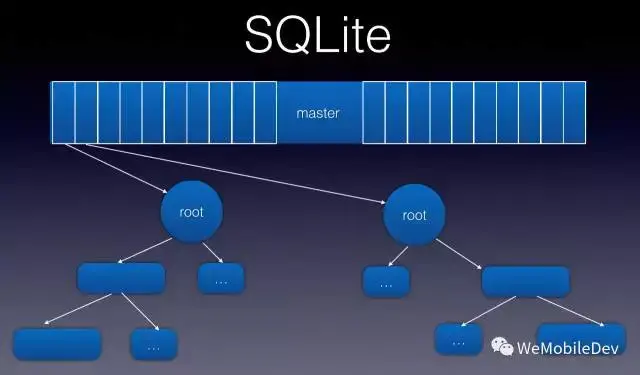
3.1、master 表
首先我们来看 SQLite 的架构。SQLite 使用 B+树 存储一个表,整个 SQLite 数据库就是这些 B+树 组成的森林。对于每个表的元数据(表名、根节点地址、表 scheme 等),都记录在一个叫 sql_master 的表中。这个 sql_master 表(下简称 master 表) 本身也是一个 B+树 存储的普通表。
3.2、官方修复算法率低下原因
官方修复算法是这样一个流程:从 master 表中读出一个个表的信息,根据根节点地址和创表语句来 select 出表里的数据,能 select 多少是多少,然后插入到一个新 DB 中。要注意的是 master 表他本身也是一个 B+树 形式的普通表,DB 第0页就是他的根节点。那么只要 master 表某个节点损坏,这个节点下面记录的表就都恢复不了。更坏的情况是 DB 第0页损坏,那么整个 master 表都读不出来,就导致整个DB都恢复失败。这就是官方修复算法成功率这么低的原因,太依赖 master 表了。
3.3、备份 master 表
那么最自然的想法,自然是另外备份一份 master 表了,也不需要用B+树,直接用数组序列化存储就好。我们只需要每隔一段时间轮询 master 表,看看最近有没有增删 table,有的话就全量备份。
3.3.1、备份时机
这里有个担忧,就是普通数据表的插入会不会导致表的根节点发生变化,也就是说 master 表会不会频繁变化,如果变化很频繁的话,我们就不能简单地进行轮询方案了。通过分析源码,我们发现 SQLite 里面 B+树 算法的实现是 向下分裂 的,也就是说当一个叶子页满了需要分裂时,原来的叶子页会成为内部节点,然后新申请两个页作为他的叶子页。这就保证了根节点一旦定下来,是再也不会变动的。实际的代码调试也证实了我们这个推论。所以说 master 表只会在新创建表或者删除一个表时才会发生变化,我们完全可以采用定时轮询方案。
3.3.2、备份文件有效性
接下来的难题是既然 DB 可以损坏,那么这个备份文件也会损坏,怎么办呢?我们采用了 双备份 的机制。具体来说就是会有新旧两个备份文件,每个文件头都加上 CRC 校验;每次备份时,从两个备份文件中选出一个进行覆盖。具体怎么选呢?优先选损坏那个备份文件,如果两个都有效,那么就选相对较旧的。这就保证了即使本次写入导致文件损坏,还有另外一份备份可以用。这个做法跟 Realm 标榜的 MVCC(多版本并发控制)的做法有异曲同工之妙,相当于确认新写入的文件有效之后,才使用新写入的文件,否则还是继续用旧的有效的文件。
前面提到 DB 损坏的一个常见场景是空间不足,这种情况下还要分配文件空间给备份文件也是会失败的。为了解决这个问题,我们采取 预先分配空间 的做法,初始值是 32K,大约可存 750 个表的元信息,后续则按照32K的倍数进行增长。
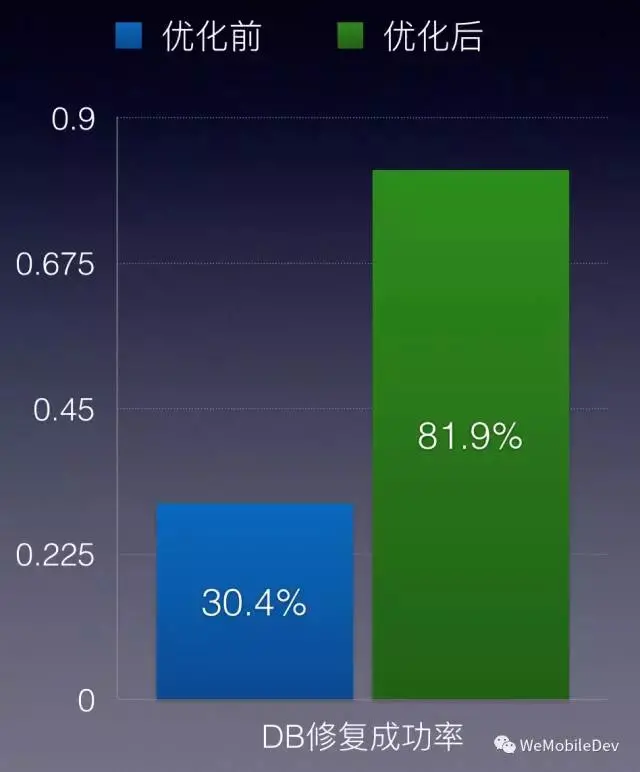
3.4、优化效果
通过备份 master 表,我们成功将修复成功率提高了一倍多。
4、其他
通过这些优化,我们提高了微信聊天记录存储的可靠性。这些优化实践,会同之前在并发性能方面的优化实践(微信iOS SQLite源码优化实践),将会合并到微信即将开源的 WCDB(WeChat Database)组件中。我们正在进行紧张的代码整理工作,争取在 2017 年年中开源 WCDB。