理解 Vision 框架中的图片技术
2020 - 04 - 27
Posted by RickeyBoy
理解 Vision 框架中的图片技术
WWDC 2019 session 222 Understanding Images in Vision Framework
Vision 是 Apple 2017 年和 Core ML 一起推出的、基于 Core ML 封装的图像识别库。根据官方文档看,Vision 包含就有人脸识别、机器学习图片分析、条形码识别、文字识别等基础功能。 本文主要介绍了 Vision 框架在图像技术方面的一些酷炫功能,并一定程度上阐述了其原理。
图片重点区域 Saliency
Saliency 是什么?
Saliency 直译成中文就是:显著、凸起、特点。那么在 Vision 框架之中,Saliency 究竟指的是什么呢?先直接上图:

当我们第一次看到左侧这张图片时,视线一定是最先被这三张鸟脸 (海雀脸) 吸引的。如果把注意力集中的地方,用高光在图片中标注出来,那么大概就是第二张图这样:高光集中于鸟的头部。 这些高光部分,也就是人类注意力更容易集中地部分,实际上就是一种 Saliency (即基于注意力的 Saliency),而高光过后的效果图实际上就是 Saliency 的热力图 (The Heatmap)。
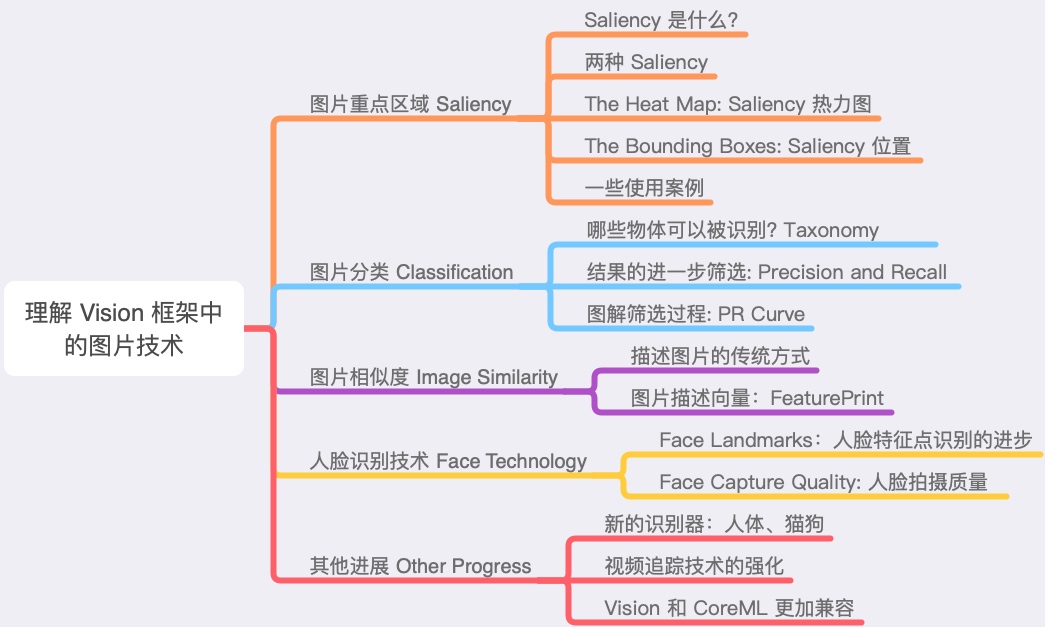
两种 Saliency
这两种 Saliency 在算法上就有着比较明显的不同。基于注意力的 Saliency 实际上就是直观的由人类注意力的集中程度来判定,而基于物体的 Saliency 目的是识别出焦点物体,然后将焦点物体分割出来。

所以效果图如上,中间的图是基于注意力的结果,我们通常关注的是人物、动物的面部,所以只有面部附近会高亮。而右边的图将整个鸟都高亮了出来,是基于物体的结果。比如下面这张图,也是同样的道理:

实际上,基于注意力的 Saliency 会更为复杂。其实我们也能直观地感受到,因为注意力本身就会受到太多人为的不确定因素的影响,比如画面对比度、人物面部、画面主题、视野范围、光线强度等。有意思的是,它甚至会被持续的运动状态所影响,比如下图中,基于注意力的 Saliency 将人物行进路线前方的部分区域也进行了高亮:

具体的 Demo 可以参见:高亮图片中令人感兴趣的部分
The Heat Map: Saliency 热力图

热力图的概念很容易理解,那么如何获取 Saliency 热力图呢?Vision API 设计的基本使用逻辑就是 handler 搭配 request。通过创建 handler (VNImageRequestHandler, Vision 图片处理中最主要的 Handler) 之后调用 perform(_:) 方法,执行相应的 request (VNGenerateAttentionBasedSaliencyImageRequest,从名字就可以看出,关键词 AttentionBasedSaliency),具体代码如下:
let handler = VNImageRequestHandler(url: imageURL)
let request: VNImageBasedRequest = VNGenerateAttentionBasedSaliencyImageRequest()
request.revision = VNGenerateAttentionBasedSaliencyImageRequestRevision1
try? handler.perform([request])
guard let result = request.results?.first
let observation = result as? VNSaliencyImageObservation
else { fatalError("missing result") }
let pixelBuffer = observation.pixelBuffer
The Bounding Boxes: Saliency 位置
var boundingBox: CGRect { get }
Bounding boxes 就是探测出来的 Saliency 的位置信息,不过需要注意的是,坐标系的原点在图片左下角。对于基于注意力的 Saliency 来说,只有唯一的 bounding box,而基于物体的 Saliency 则最多有三个 bounding box。

获取 bounding box 代码如下:
func addSalientObjects(in observation: VNSaliencyImageObservation,
to path: CGMutablePath,
transform: CGAffineTransform)
{
guard let objects = observation.salientObjects else { return }
for object in objects {
// 得到 bounding box
path.addRect(object.boundingBox, transform:transform)
}
}
一些使用案例

得到图片 Saliency 之后其实有很多作用,具体举几个例子:
- 用于滤镜:增加不同类型的滤镜、图片效果。
- 用于相册:增加图片浏览的体验,将照片自动缩放到最佳位置。
- 用于识别:与其他图像算法一起使用,先通过 bounding box 将物体切割出来,之后进行再识别提高准确率。
图片分类 Classification
图片识别、分类是 Vision 的最基础功能,Vision 框架提供了用于图片分类的 API,使用起来非常方便,iPhone 相册中就有大量使用。虽然 coreML 框架也能使用自己训练图片分类器,需要大量的数据以及计算资源等,对于普通开发者来说具有比较大的成本。而且 Vision 框架使用了多标签分类网络(Multi-label network)可以在一张图里面识别出多个物体。
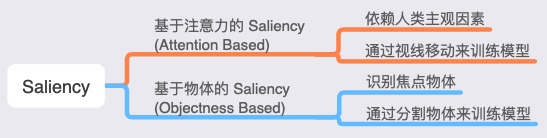
哪些物体可以被识别? – Taxonomy
到底哪些 object 可以被识别?这就要引出 Taxonomy 的概念了。Taxonomy 实际上指的是生物学上的分类系统,不同物体根据语义上的含义被分类。在这个树状结构中,有超过 1000 个分类,父类更加宽泛,子类更加具体。
也可以通过下面的语句,查看整个 Taxonomy:
// List full taxonomy with
VNClassifiyImageRequest.knownClassifications(forRevision: VNClassifyImageRequestRevision1 )
在构造这个 Taxonomy 树状结构时,每个分类都必须是可以通过视觉定义的,必须要避免形容词、抽象名词、太宽泛的名词,以及避免职业名称。具体使用,也符合 Vision API 统一的使用方法,handler (依然是 VNImageRequestHandler, Vision 图片处理中最主要的 Handler) 搭配 request (VNClassifyImageRequest,关键词 Classify,分类识别专用):
let handler = VNImageRequestHandler(url: imageUrl)
let request = VNClassifyImageRequest()
try? handler.perform([request])
let observations = request.results as? [VNClassificationObservation]
最终得到一个 Observation 数组,包含一系列物体识别结果,以及分别对应的信心值(可能性)。注意到信心值总和不为 1,这就是因为刚才提到的 Multi-label network 所产生的结果。

// 上图识别之后的 observations 示例结果
// 从图中识别出可能有:动物、猫、哺乳动物、衣服、小圆帽、帽子、人、成年人、雪...等一系列结果
[(animal, 0.848), (cat, 0.848), (mammal, 0.848), (clothing, 0.676), (beanie, 0.675), (hat, 0.675), (people, 0.616), (adult, 0.616), (snow, 0.445), (jacket, 0.214), (outdoor, 0.063), (leash, 0.057), (cord, 0.057)......]
结果的进一步筛选: Precision and Recall
得到识别结果之后,如何 Observation 数组进行进一步分析,来判定究竟识别结果中哪些是足够可信的呢?非常符合常识的一个关键公式是:Confidence > Threshold。很容易理解,当信心值大于某个阈值时,就可以判断图片中有相应物体。但是最大的问题在于,阈值应该如何确定,并且阈值并不固定,不同的图片中阈值肯定是不同的。 接下来,我们需要先引入两个指标:Precision 查准率、Recall 召回率。用一张比较经典的图来解释一下:

- Precision 查准率,指的是所有预测中真正预测对的比例。它能够反映出误报的程度。Precision 率越高,代表预测的越准确,误报数量越少。
- Recall 召回率,指的是所有符合要求的结果中,被成功预测出来的比例。它反映的是漏报程度。Recall 率越高,代表预测的越准确,漏报数量越少。
Precision 和 Recall 都能反映分类算法的准确性,但却有不同的倾向性。举两个例子,比如 AI 看病时,通常更看重 Recall 召回率,因为我们更担心漏报情况的发生。而比如在过滤垃圾邮件时,通常更看重 Precision 查准率,毕竟我们不希望错误地把用户的正常邮件也给错误地过滤了。 所以回到最初的问题,我们如何判定 Observation 数组中哪些结果是符合 Confidence > Threshold 公式,应该被留下来的呢?我们可以直接通过限制 Precision 或者是 Recall 的值来拿到结果。 比如使用 hasMinimumRecall(_:forPrecision:) 限制 recall,precision 为 0.7 时,最小 recall 为 0.5:
let searchObservations = observations?.filter { $0.hasMinimumRecall(0.5, forPrecision: 0.7)}
当然,使用 hasMinimumPrecision(_:forRecall:) 限制 precision 也是同理:
let searchObservations = observations?.filter { $0.hasMinimumPrecision(0.5, forRecall: 0.7)}
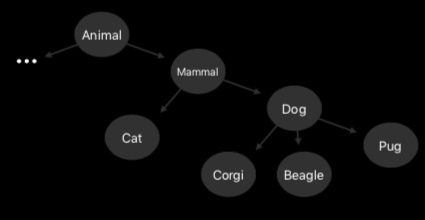
图解筛选过程: PR Curve
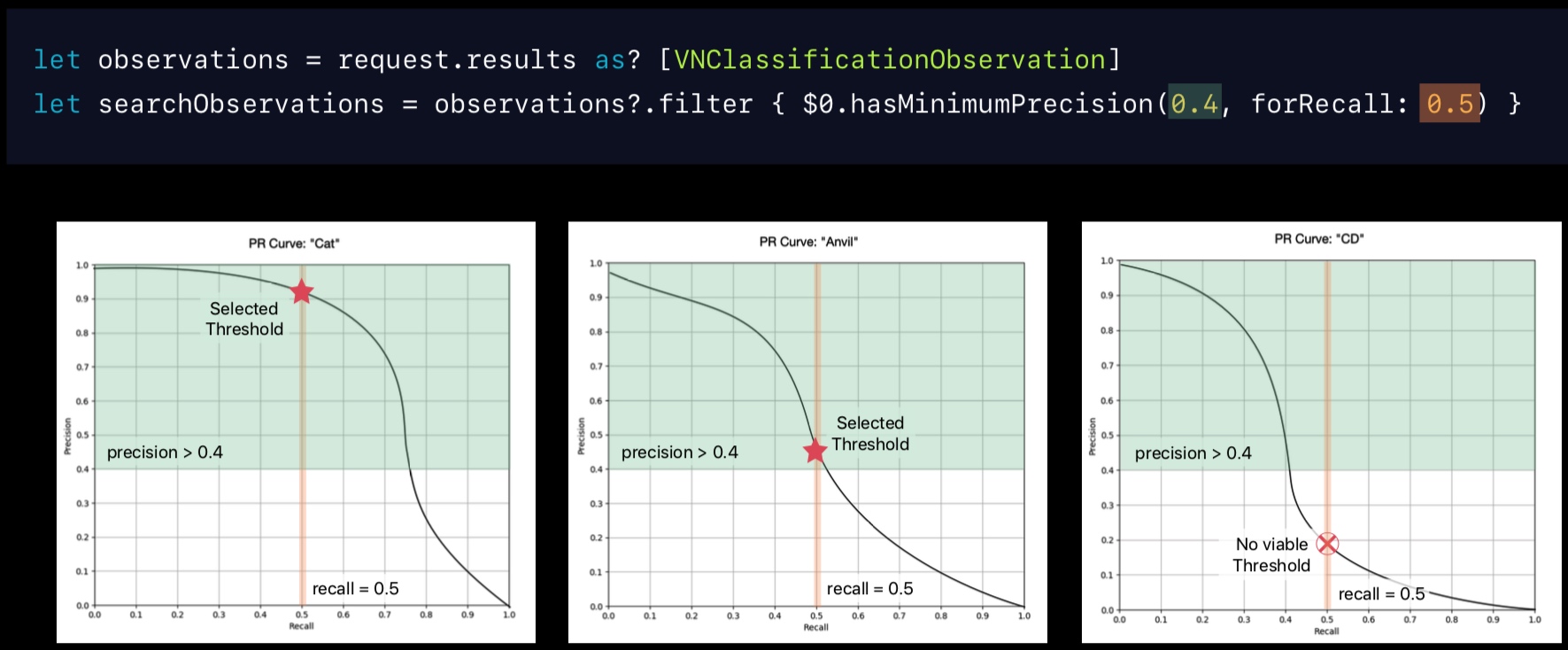
PR 曲线反映的是同一个分类器下 Precision 和 Recall 的关系,可以用来衡量分类器性能的优劣。可以看到 Precision 和 Recall 负相关。
对于 PR 曲线上每一个点,都对应着一个 Precision 和 Recall 的值。我们可以通过 PR 曲线来直观地理解上文中筛选、过滤的这个过程。比如下面我们分别有三个分类器,分别对应识别”Cat”、”Anvil”以及”CD”时的 PR 曲线。当我们限制了 (Recall = 0.5, Precision >= 0.4) 时,可以看到前两张图都存在买组条件的点,而第三张图并不存在,那么很明显的 “CD” 就应该被从结果中过滤掉。
图片相似度 Image Similarity
描述图片的传统方式
除了识别图片的问题之外,我们经常会面临的问题就是,如何判断两张图片间的相似程度。那么首先,我们该如何描述一张图片?传统的方式有下面两种:
- 使用像素点信息进行比较。这样比较非常不准确,小小的改动就会完全判定为不同图片。

- 使用关键词。但是关键词对于一张图片来说过于笼统,不够精确。

对于一个图片的描述,不能仅仅包含对其表面样式的描述,还必须包含对图片的内容的进一步叙述。用上述传统方法我们很难实现所谓的”进一步描述”,但是巧妙的是,当我们在用分类神经网络对图片进行分类时,神经网络本身就是对图片的进一步描述。神经网络的上层网络(upper layers)正好包含了图片的关键信息(salient information),同时也恰好能摒弃掉了一些冗余信息。所以,我们可以利用这个特点,来对图片进行描述。
图片描述向量:FeaturePrint
FeaturePrint 用于描述图片内容的向量,和传统的词向量 (word vector) 类似。它反映的就是神经网络在做图片分类时,从图片中提取出来的信息。通过特定的 Vision API,就能将图片映射成对应的 FeaturePrint (这也是为什么说它是一种向量)。 需要注意的是,FeaturePrint 与 Taxonomy 并不相关,并不是说图片被分类为猫,那么对它的描述就应该是猫。 在得到了 FeaturePrint 之后,我们就可以直接比较图片间的相似程度。computeDistance(_:to:) 方法可以直接得到一个反映图片相似度的浮点数。比如下图中,数值越小,图片在语义 (semantic sense) 上越相似。

具体 Demo 参见:Demo - 使用FeaturePrint比较图片间相似度
人脸识别技术 Face Technology
接下来讲一下人脸识别技术方面的进步。
Face Landmarks: 人脸特征点识别的进步
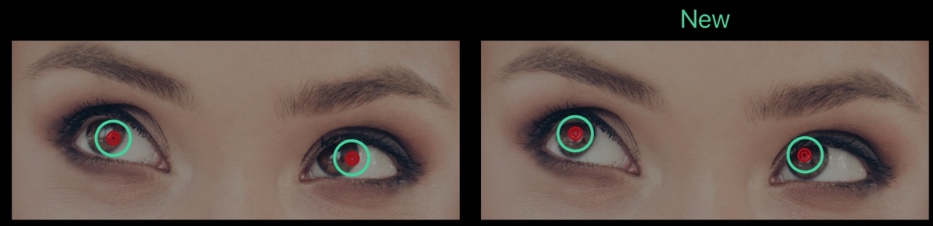
人脸特征点 (Face Landmark) 的识别一直是人脸识别技术的重要部分,Vision 框架在这方面有下面几个进步:
- 识别点位增加,从 65 到 76 个点
- 每个点都提供了信心度 (之前只能提供一个整体的信心度)
- 瞳孔识别更加精确

Face Capture Quality: 人脸拍摄质量
Face capture quality 是一个综合性指标,用于判定人像效果的好坏,衡量因素包含光线、模糊程度、是否有遮挡、表现力、人物姿态等等。

比如第一张照片就比第二张照片得分高,意味着第一张照片有着更好的拍摄质量。

我们可以通过上面的代码,直接得到一张图片的 face capture quality 的数值,进而将相似图片进行比较,筛选出更加优质的图片。比如这里个 Demo:根据 face capture quality 筛选自拍照
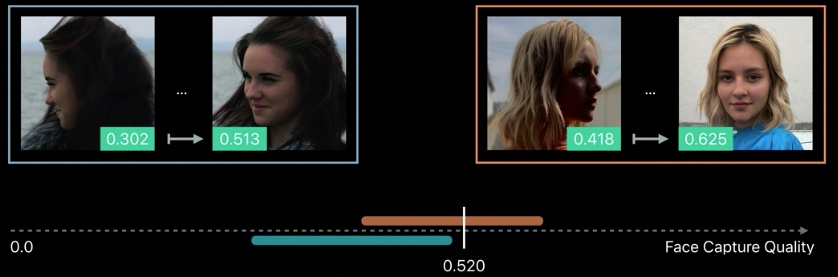
注意,face capture quality 不能和一个固定阈值进行比较。不同系列的照片中 face capture quality 值分布区域可能不同,如果我们以一个固定的阈值来过滤(比如上图中的 0.520),那么有可能会把左边全部的照片都过滤掉,哪怕其实左边的图片有一些相对拍的好的照片。换句话说,face capture quality 只是一个对同一个被摄物体的相对值,它的绝对数值大小并不能直接反映照片的拍摄效果。
其他进展 Other Progress
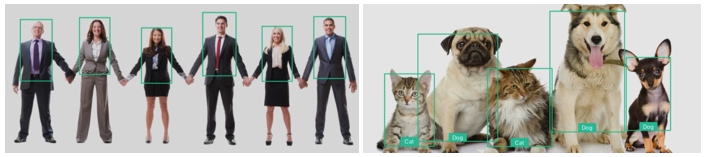
新的识别器
除了这些传统的识别器,还有一些新的比如人体 (Human Detector) 和猫狗 (Cat and Dog Detectors) 的识别器。
视频追踪技术的强化
视频追踪技术也得到了强化,追踪技术的 Demo 可以查看: 在视频中追踪多个物体。具体强化内容如下:
- Bounding box 更加贴合,减少了乱入的背景
- 更好处理有遮挡的情况
- 依赖了机器学习算法
- 更低的能量损耗
Vision 和 CoreML 更加兼容
Vision 对 CoreML 的支持也得到了提升。虽然去年就可以通过 Vision API 运行 CoreML 的模型,但是现在使用起来更方便:
- Vision 能自动将输入的图片转成 coreML 的格式,输出后又自动解析为合适的 Observation 类型。
- Vision 可以将多个图片作为输入了,不过需要需要设置 mixRatio。