让所有网页变成RSS —— Huginn
2018 - 07 - 26
Posted by judi0713
如果你不知道什么是 RSS,赶紧去查查是什么然后用起来吧,相信我,用了就再也离不开了。
我是一个重度 RSS 使用者,一般来说,我获取信息有微博,微信,邮件,还有就是 RSS 。每次打开 Chrome 之后第一个打开的就是 Feedly,看看有没有新的内容更新,省去我了一次性打开多个网站的麻烦。但是问题来了,有些网站没有 RSS 怎么办?
前几天在利器的群里,看到有在讨论一个叫 Huginn 的东西,一个叫祥子的朋友还很热心的给大家解答一些关于这个的问题,我稍微查了查,发现这个东西可以解决我一直的一个痛点,就决定花时间来倒腾一下。
Huginn 是一个 Github 的开源项目,已经上万 Star 了。简单的说这个东西是一个 IFTTT 形式的东西,可以把所有网页转换成 RSS 输出。更简单的说,就是工作流形式,类似于 iPhone 上的 Workflow。
安装
建议采用 docker
Docker hub地址
官方文档安装教程地址
使用
使用的方式我捉摸了很久才搞定..我会举个把网页转换成RSS的详细的例子。
开始之前首先需要解释几个东西。
- 网页的格式是 html,RSS 的格式是 xml。
- xpath 是你用来确定网页元素的方法,这一步我会有一个很简单的方法来教大家怎么去搞定元素的确定。
- 由于是工作流的形式,所以我们整个的过程其实有两步,第一步是抓取网页的信息,第二步是返回 RSS 的地址。
下面开始举例子。我们现在要把我的博客 http://walkginkgo.com/转换成 RSS。
按照3中说的,我们需要先抓取网页信息。抓取网页信息,要创建一个 Website Agent。
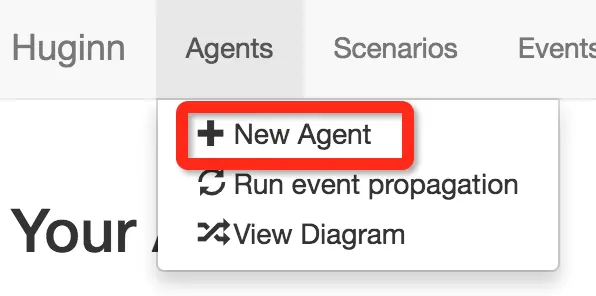
按照图示,名字随便起,其他可以先默认。(全部解释太麻烦)
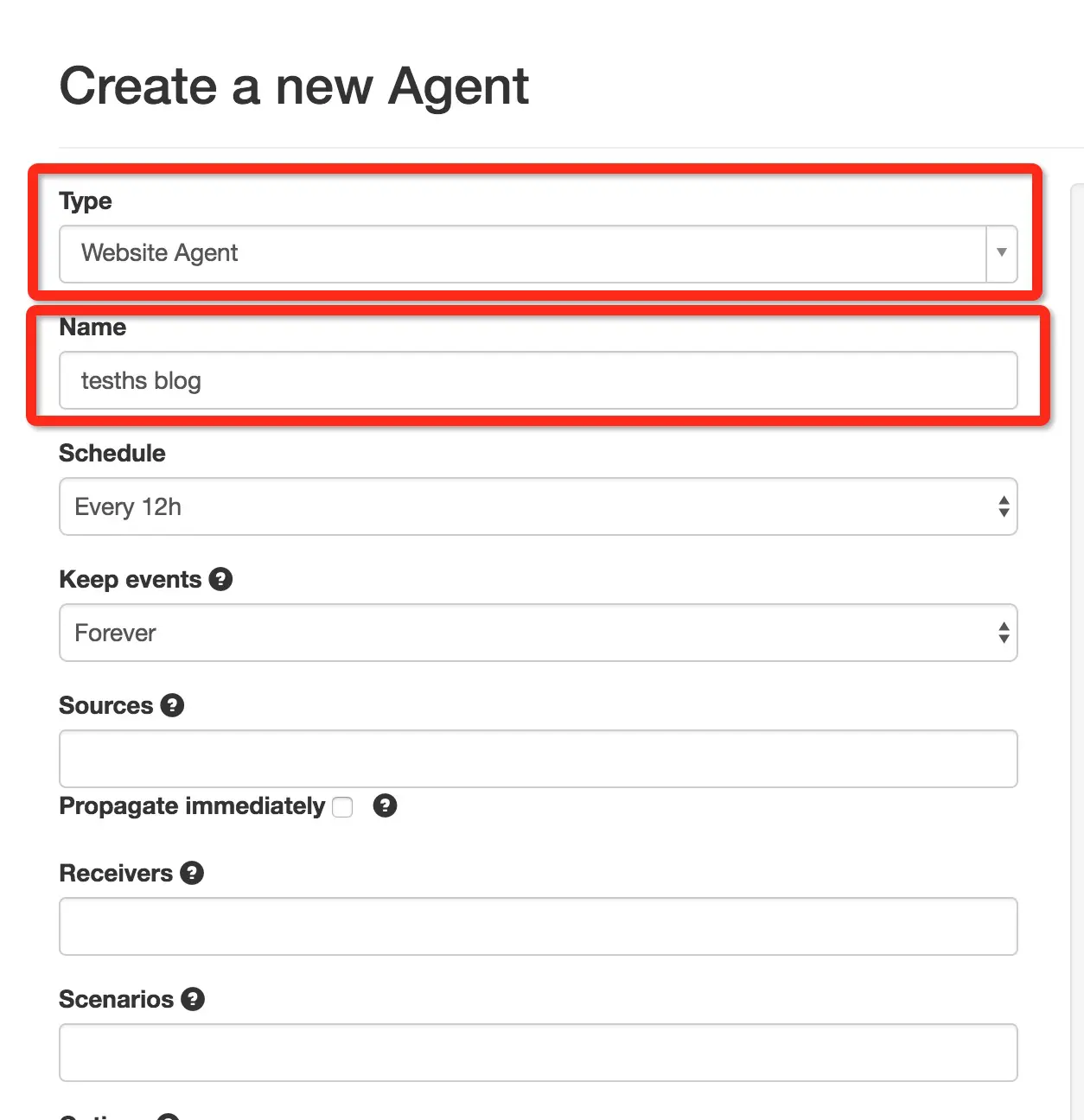
然后是关键的一步,我们要开始确定网页的元素。
点击 Toggle View 到文本编辑模式。我们要修改我圈出来的两个地方。
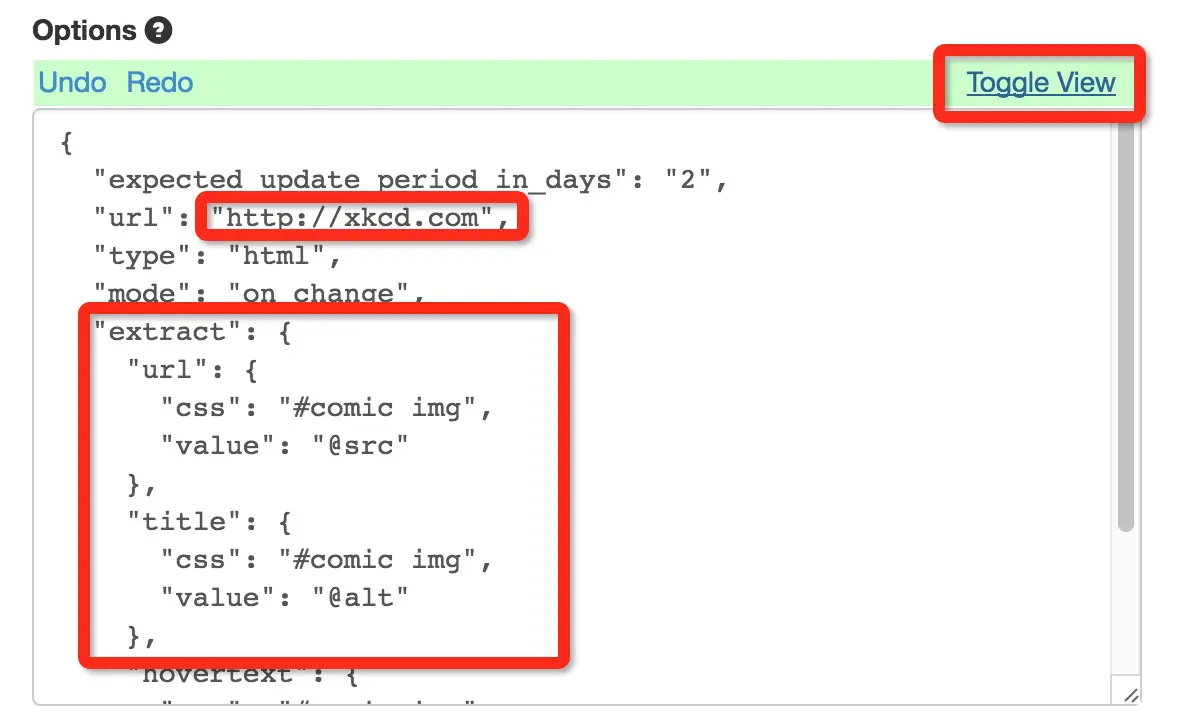
我们需要修改url到我们的网址,在这里就是 http://walkginkgo.com/ 了。
extract 是我们要提取的信息,我们这里要提取博客的题目,网址,发布日期,简述。
我们现在打开tesths这个博客进去来看怎么抓取元素。
在 Chrome 打开,然后选择你要的元素,右键选择 Inspect。可以看到 Chrome 下面的审查元素信息已经出来了。
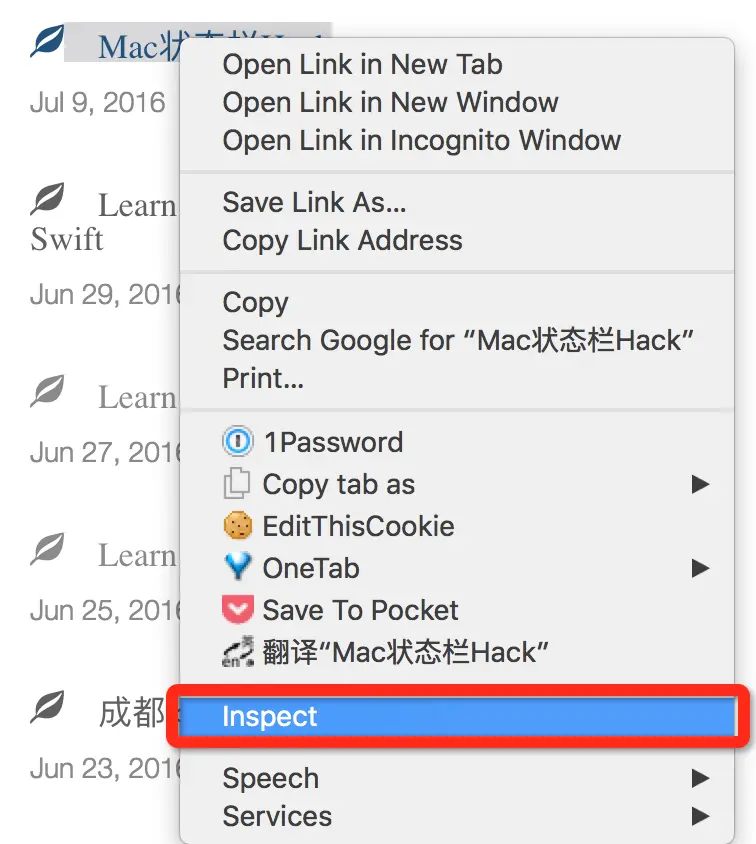
可以看到我们的元素在 span 标签里,这时候我们如图右键选择之后然后复制。

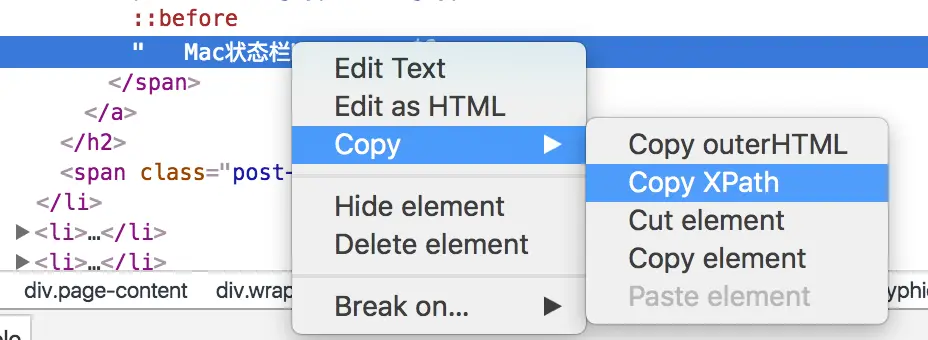
复制的东西如下。
/html/body/div[1]/div/div/ul/li[1]/h2/a/span/text()
把之前的 css 改成 xpath 然后直接复制就可以了。点击下面的 Dry Run,可以看到我们的标题已经搞定了。(css 使用见下面备注)

但是还有两个问题,一个是,我们只爬了一个标题,二是标题有空格。
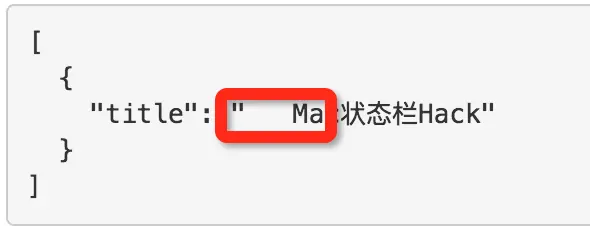
解决问题1,需要把我们的 xpath 改成这样。
/html/body/div[1]/div/div/ul/li/h2/a/span/text()
是因为 li[1] 代表我们第一个标题,所以把[1]去了就可以了。
解决问题2,需要我们加上一句话。
"value": "normalize-space(.)"
这句话的意思就是把空格去了。
最后就是这样。

下面我们把链接按照这个方法也爬下来。找到链接的地方,因为链接在a标签里面,所以我们要加一个 value,选择到 href。剩下我就不具体叙述了,我把最后完整的截图出来。

日期什么的方法类似,也不多说。这样其实没有什么 html 的基础也可以爬网页了。

Dry Run 之后的结果如图。
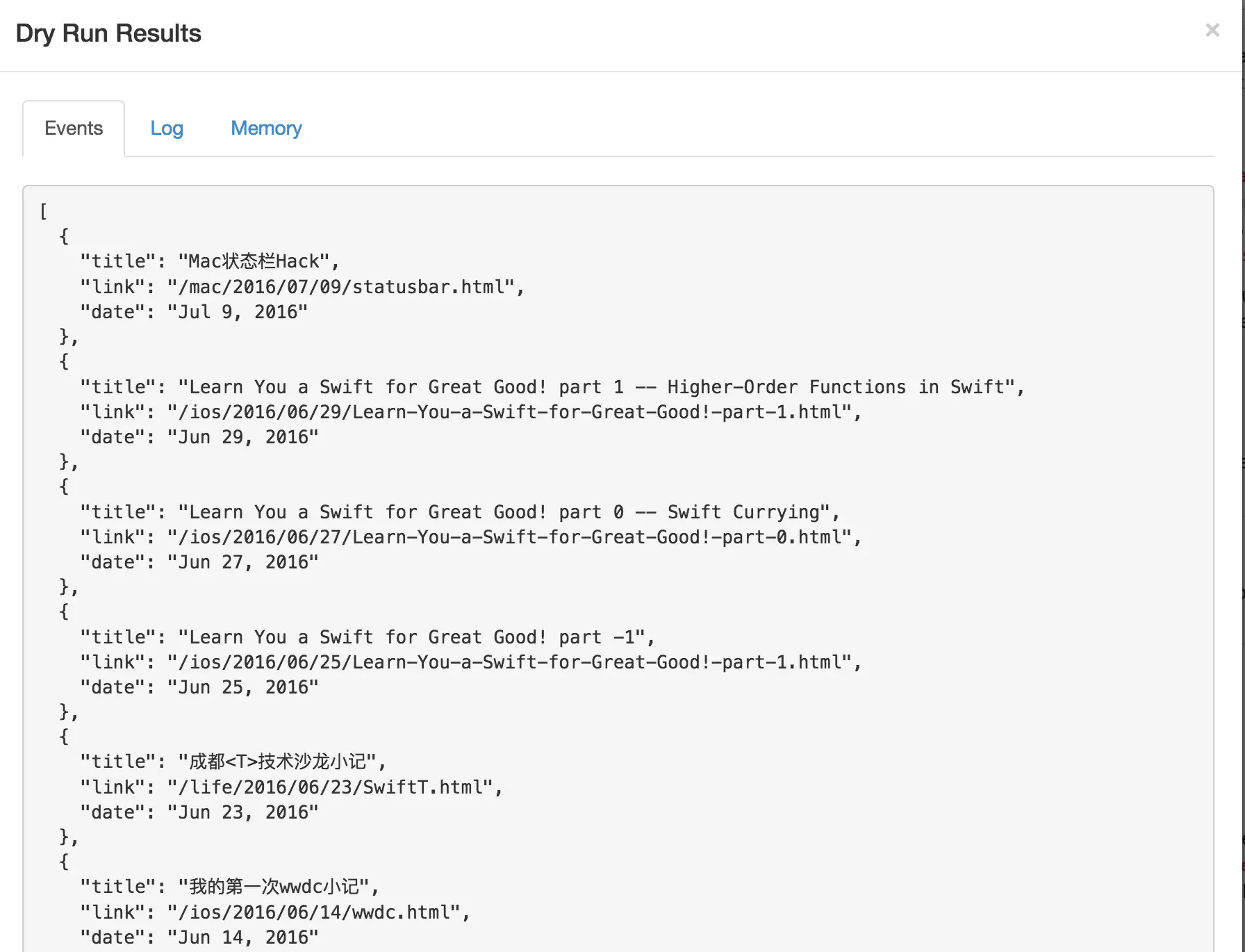
别忘记 Save。
备注:官方默认创建用的是 css,Chrome 提供了复制 css 的方式,格式稍微改动成和官方例子那样空格来代替>就可以了。
这么我们就完成了工作的第一步,抓取网页,下一步要输出 RSS。
前面都随便写,记得 Sources 选择我们之前的 tesths blog。
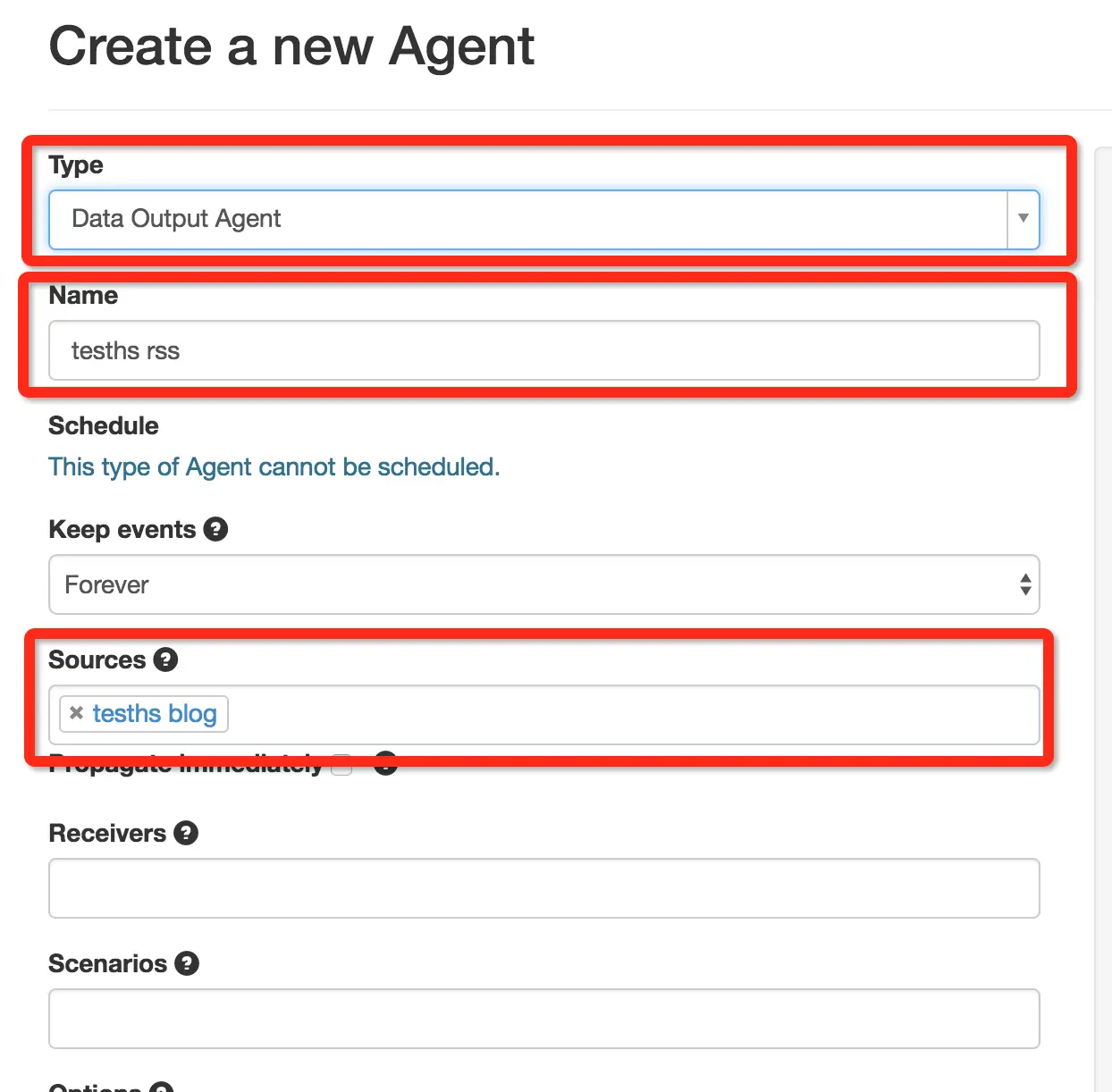
下面是继续配置 Option,这就比之前简单了。
但是注意我们之前的链接没有前面的 http://walkginkgo.com/ 这一串,我们要加上。
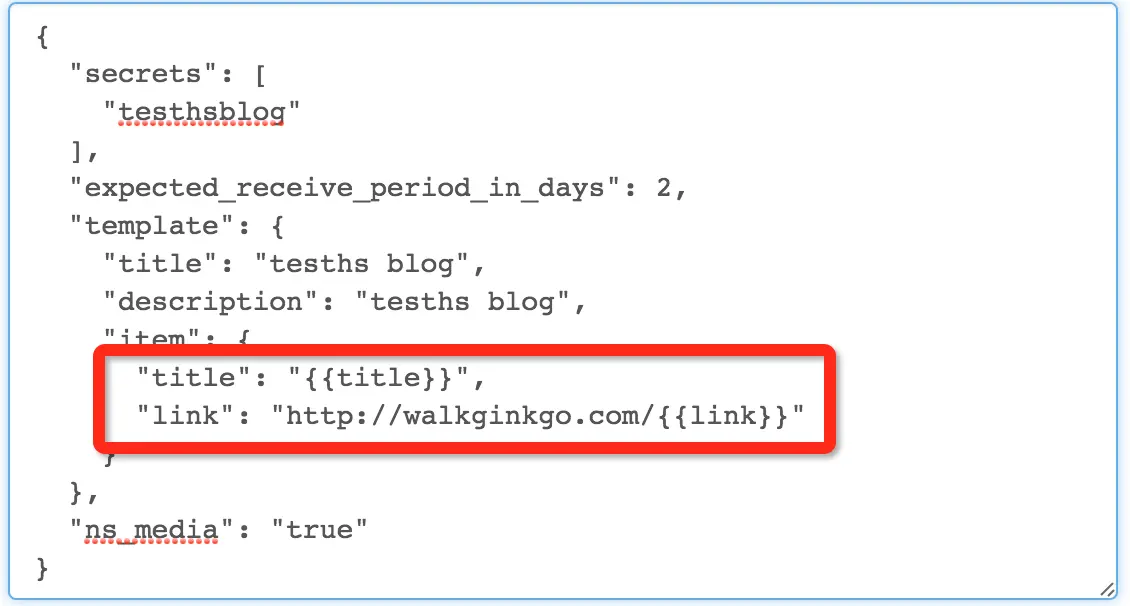
最后完整的是这样的。

还要记得把你博客的 link 加上。
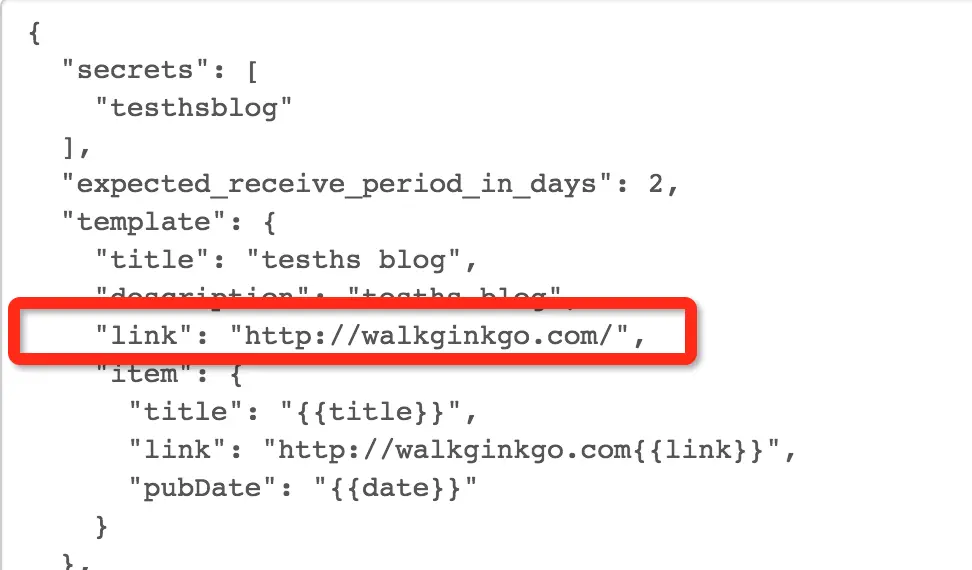
之后选择 Save 就到了这。
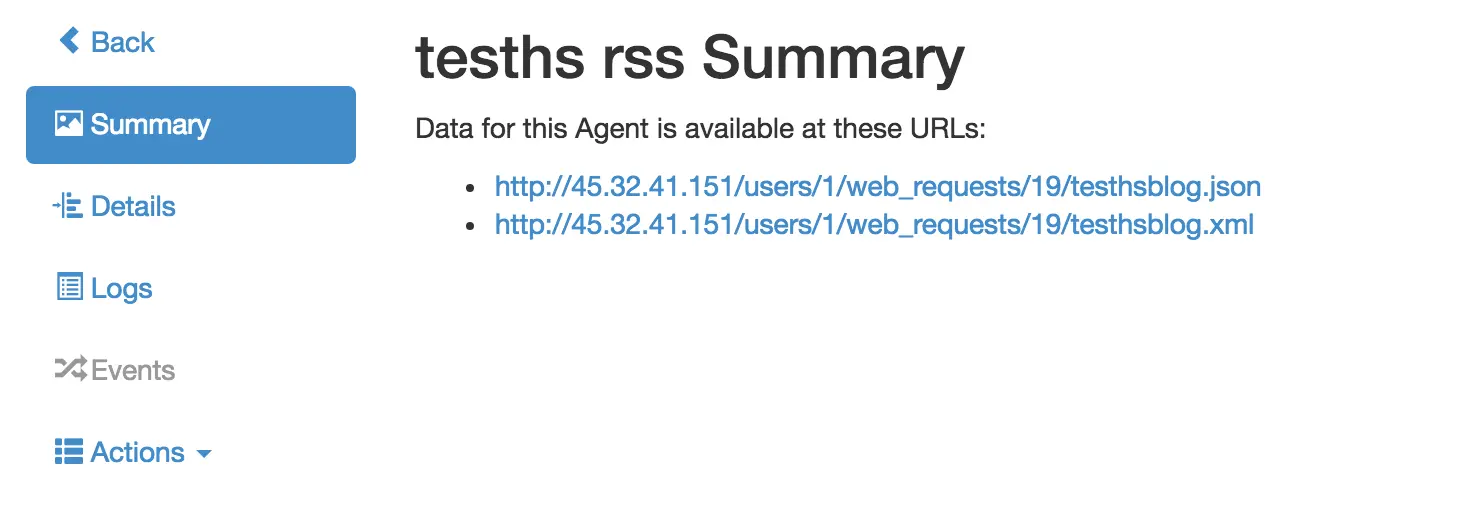
可以看到已经有 xml 格式的输出了。
最后一步我们要烧录 RSS。用到的时谷歌家的服务 feedburner
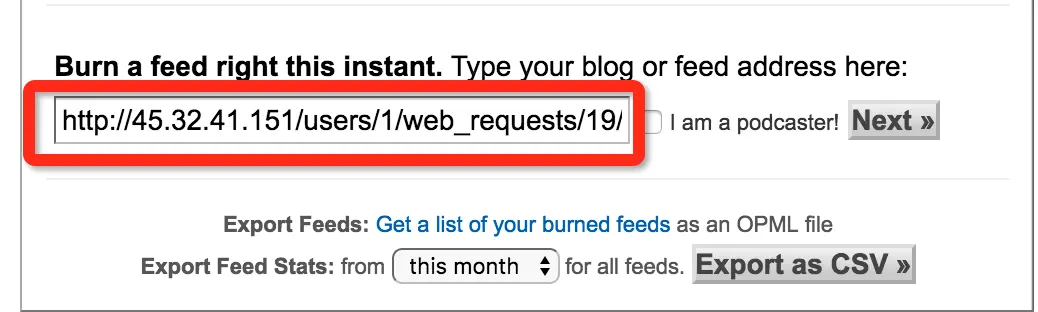
然后next。
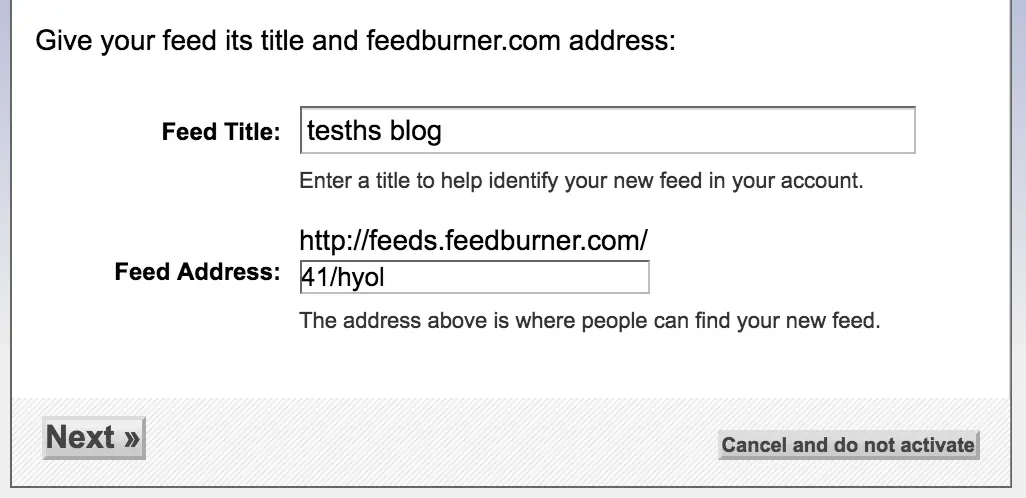
继续next。

把网址复制到 Feedly 里面,大功告成!
更多备注
因为我个人 RSS 主要是看有没有更新,所以抓取的内容不详细,需要抓取全文在手机看的话就自己倒腾啦。
如果输出 RSS 没有结果的话,可以看下是否允许,没运行点击一下 run 就可以了。

如果你遇到输出的结果有问题,可以看下是不是event多了。

如果多了就全部删除重新运行。
总之真的没有很难,最难的是 xpath 获取元素,但是我已经用了最简单的方式来教大家了,剩下的无论是不是专业学编程的都能很快搞定啦,就看大家怎么去玩这个了。
至于抓取 RSS 的频率,正在测试中..敬请关注更新。
参考链接