Python3使用Requests抓取网页乱码问题
2018 - 12 - 06
Posted by amita
1. 问题1
import requests
r = requests.get(url)
print r.text
结果乱码!
分析
with open('a.html', 'wb') as f:
f.write(r.content)
用编辑器打开一看,非文本。用命令 file a.html 一看,识别为 gzip 格式。原来返回数据经过了 gzip 压缩。
难道要自己判断格式并解压缩?
搜了下,发现 requests 支持 gzip 自动解压,这里为何不行?难道网站返回的编码有误?
print(response.headers['content-encoding'])
返回的确实是“gzip”,怎么没有自动解压?
经过坑die的探索,终于发现response.headers['content-encoding']的值其实是“gzip ”,右边多了几个空格!导致无法识别。
这个锅谁来背?request 库还是网站??
解决方案
1. Request header 里移除 ”Accept-Encoding”:”gzip, deflate”
这样能直接得到明文数据,缺点:流量会增加很多,网站不一定支持。
2. 自己动手,解压缩,解码,得到可读文本
这也是本文使用的方案
2. 问题2
print(response.encoding)
发现网页编码是 ‘ISO-8859-1’,这是神马?
《HTTP权威指南》第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是’ISO-8859-1’编码。这处理英文页面当然没有问题,但是中文页面就会有乱码了!
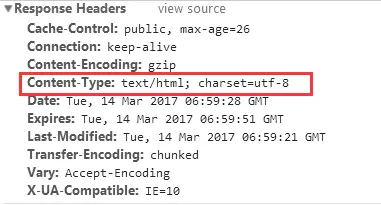
分析
1\. print(r.apparent_encoding)
2\. get_encodings_from_content(r.content)
- 据说使用了一个叫chardet的用于探测字符集的第三方库,解析会比较慢。没装,结果是 None
- 网上很多答案如此,应该是 python2 的,因为 3 里的 r.content 是 bytes 类型,应改为
get_encodings_from_content(r.text),前提是 gzip 已经解压了
3. 源码
代码如下, 基于Python 3.5
# 猜测网页编码
def guess_response_encoding(response):
if response.encoding == 'ISO-8859-1':
if response.content[:2] == b"\x1f\x8b": # gzip header
content = gzip.decompress(response.content)
content = str(content, response.encoding)
else:
content = response.text
encoding = get_encodings_from_content(content)
if encoding:
response.encoding = encoding[0]
elif response.apparent_encoding:
response.encoding = response.apparent_encoding
print("guess encoding: ", response.encoding)